La utilización de inteligencia artificial para detectar enfermedades a partir de imágenes médicas es un campo sumamente prometedor para mejorar los sistemas de salud en el mundo, con utilidades que podrían haberse aplicado en la respuesta a la pandemia provocada por el covid-19. Sin embargo, quedan muchos retos por delante para que estas técnicas sean de amplio uso.
El primer reto por solucionar es la recopilación de datos. Luego, que los modelos de inteligencia artificial tengan la capacidad de operar con alta exactitud a pesar de trabajar con conjuntos de datos de distintas fuentes y distribuciones.
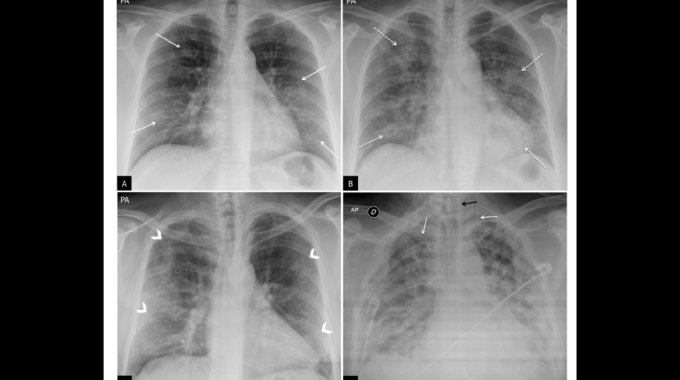
Este es el planteamiento de la investigación del M.Sc. Saúl Calderón Ramírez, quien está por terminar sus estudios de doctorado en el Instituto de Inteligencia Artificial, de De Montfort University, [2] en Leicester, Inglaterra.
“El enfoque del trabajo fue averiguar qué sucede cuando entrenamos un modelo semisupervisado que usa datos no etiquetados y etiquetados en el contexto de imágenes médicas. Usar datos etiquetados es muy caro. Cuando entrenas un modelo, por ejemplo con datos del Hospital México, es necesario usar datos de ese mismo hospital, porque cuando usamos datos de otros hospitales para su uso cotidiano, el modelo tiende a tener un rendimiento mucho menor. Esto, dado que el modelo se entrenó con datos de pacientes con fisonomía diferente o con imágenes adquiridas con distintos parámetros.
“Entonces, por eso es que es atractivo usar datos no etiquetados porque no ocupas de mucha supervisión”, detalló Calderón.
Según el investigador, la ventaja final de utilizar datos de diferentes conjuntos o lotes de procedencia es que mejora la capacidad de “aprendizaje” de los modelos computacionales y, con esto, el porcentaje de acierto.
Calderón forma parte del grupo especializado de investigación Parma [3] (Pattern Recognition and Machine Learning), del TEC, en el cual ya ha liderado investigaciones para detectar cáncer de mama por medio de mamografías.
En sus estudios doctorales, se enfocó a estudiar el impacto y mitigación de las distribuciones diferentes entre el conjunto de datos etiquetado y no etiquetado en aplicaciones de análisis de imágenes médicas. Parte de su investigación la hizo con imágenes de rayos X de tórax para la detección de covid-19.