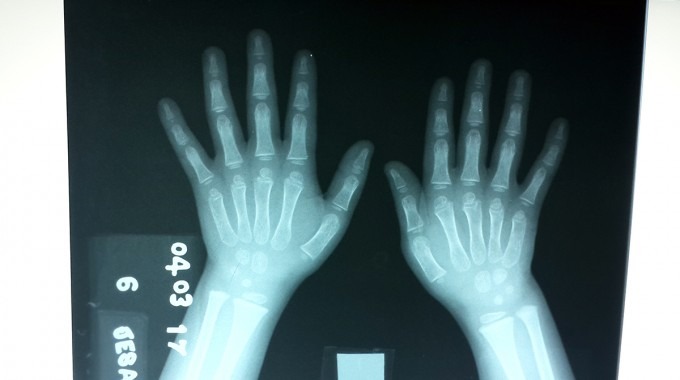
Expertos del Tecnológico de Costa Rica [2] (TEC) crearon un modelo computacional que utiliza imágenes de rayos X para determinar la edad de infantes, con precisión de meses. Ahora desarrollan una aplicación que le ayudará a los médicos a diagnosticar trastornos de crecimiento.
Los especialistas del Grupo Parma (PAttern Recognition and MAchine Learning Group), un combinado de investigadores en computación avanzada y aprendizaje automático, demostraron que la utilización de filtros previos para tratar imágenes mejora en un 42% la efectividad con la que las computadoras pueden determinar la edad de los niños a través de radiografías de su mano izquierda.
El estudio logró avances considerables, por lo que un artículo al respecto fue aceptado para presentarse en la edición de este año de la Conferencia Internacional sobre Procesamiento de Imágenes [3] de la IEEE, que se realizará en octubre en Atenas, Grecia, y se considera la más importante en este tema.
En el paper participaron los investigadores Saúl Calderón, Manuel Zumbado y Martín Solís, del TEC, y Fabián Fallas, quien trabaja en el TEC y la Universidad de Costa Rica (UCR); con la colaboración de colegas de la Universidad de Toronto, Canadá, y la Universidad de Ljubljana, Eslovenia.
“Que un software pueda tomar una imagen de rayos X y pueda decir cuál es la edad estimada de un niño, en meses, es muy relevante en medicina; porque si un técnico recibe a un niño, le saca una imagen de rayos X y resulta que el software dice 30 meses, y el niño tiene más o menos edad, entonces eso le ayuda a diagnosticar algún problema de crecimiento.
“Entonces esto da un soporte al médico para poder diagnosticar, o dar datos más certeros de cuál es la evolución del niño”, detalla Fallas.
Utilidad
Si el sistema determina que la edad ósea de los infantes no corresponde a la edad real del paciente, eso es una señal clara de que existe un trastorno endocrino o metabólico que está afectando el crecimiento de la persona.
Según Calderón, ya se hizo un contacto con el departamento de radiología del hospital Max Peralta, en la ciudad de Cartago, para poner a su disposición una aplicación que les permita sacar provecho del modelo computacional. También espera facilitar el sistema al Hospital Nacional de Niños.
Además, se trabaja para aplicar estos sistemas de procesamiento y análisis de imágenes en el diagnóstico médico asistido por computadora para otro tipo de enfermedades, como el cáncer.
“La idea no es reemplazar al experto, sino darle una asesoría mucho más rápida. Son muchos datos los que los médicos tienen que procesar y a veces no tienen cómo evaluar mediciones exactas de cosas tan pequeñas como células”, explica Calderón.
Sin embargo, comenta el especialista, para que este tipo de modelos computacionales sean efectivos se requieren gran cantidad de datos y en Costa Rica –como en casi todo el mundo– los sistemas de salud carecen de una cultura de recopilación, digitalización y sistematización de la información.
“El problema es que se necesitan muchos datos para entrenar esos modelos, hablamos de miles de miles de imágenes (...). Así que hay que trabajar mucho en culturizar a esas organizaciones de cómo generar esos datos, de generar buenos datos también, es importantísimo, y es algo que es prácticamente nulo en sistemas de salud públicos o privados”, agrega Calderón.
Mejoría sustancial
Los especialistas del Grupo Parma utilizaron una técnica de inteligencia artificial conocida como Deep Learning para que el modelo “aprendiera”, por medio del análisis de una gran cantidad de imágenes, a identificar la edad de los sujetos a los que pertenecen las radiografías.

En este caso los investigadores utilizaron 12.000 imágenes de rayos X de la mano izquierda de hombres y mujeres de entre los 0 y 19 años de edad, tomadas de una base de datos pública que facilitó la Asociación Radiológica de Norte América (RSNA, por sus siglas en inglés).
La novedad que aportaron los investigadores del TEC y la UCR fue utilizar filtros para mejorar la calidad de las imágenes antes de que fueran procesadas. Esto los llevó a mejorar en 42% la efectividad del sistema.
“Es muy interesante porque en la literatura autores anteriores que han estudiado este tema sí usan técnicas de pre-procesamiento, algunos filtros, pero no le han dado el énfasis que debería dársele; porque tradicionalmente se ha creído que estos modelos de Deep Learning aprenden de forma completamente autónoma, a través de los datos, que no es necesario procesar los datos de alguna forma.
“Se cree que no se debe eliminar ruido, porque está introduciendo un sesgo al modelo. pero aquí comprobamos que no es así”, argumenta Calderón.
Para procesar toda esta información y validar los resultados, se requiere de un gran poder por computación, por lo que los ingenieros acudieron a las facilidades del Centro Nacional de Alta Tecnología (CeNAT) [4], que les facilitó el acceso a equipo de forma remota para realizar su investigación.
“Aquí el tema del uso de los datos va en crecimiento y la industria ya tiene la necesidad de personal que esté calificado para desarrollar sistemas de este tipo. Es todo un tema complejo, porque va desde definir cuáles datos recopilar, qué preguntas podemos resolver, construir el sistema, validarlo, etcétera”, asevera Calderón.